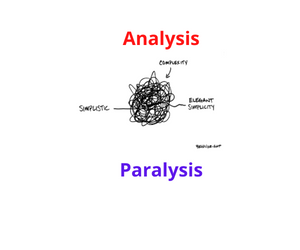
Data quality is either the root of all evil or the fountain of all good. My view is that 80% of the time, evil wins.
Data quality is not just a challenge for the big behemoth banks, it is even a challenge for new businesses that thrive on new technology, practice all things Lean & Agile and are not dragged down by all those legacy and technical debt issues that plague established banks.
Spotify is very widely beloved of music listeners and also praised for its agile work practices. I am one of those fans. I also like a new feature that tells me about upcoming local concerts by artists whom I have listened to. I never specifically signed up for this, it just happened, but I really can appreciate what is arguably a bit of machine learning or robotics in the background.
A few weeks ago, Spotify told me about a September concert by James Taylor. Even had a nice picture of the famous man in the mailing. Excellent idea. I saved the mail and this weekend decided to book some tickets. To my surprise, Spotify had messed up. Their link was to an upcoming concert here in Zurich by the James Taylor Quartet. Whoops!
I will bet that the root of the error is that there is not a unique identifier for musicians. The point though is that data is hard to manage in all industries. Even the oh so fashionable and up to date tech crowd at Spotify can and do fall over.
In the financial services world, I would say that Data Quality is of massive importance. There are really big forces at work: Big Data, Digital & Digitalisation are the buzzwords du jour. Simply put, if the data is poor, then the shiniest tools will not help you: garbage in, garbage out!
Understanding where data quality breaks down is very important. Away from those buzzwords, there are three key forces bearing down on bad data:
Regulatory demand. There are more demands and they are more frequent. BCBS 239 on Risk Data Aggregation and Risk Reporting (RDARR) is an example, BCBS 248 on intraday liquidity. For the 30 large global institutions designated as G-SIBs, Globally Systemically Important Banks, membership of that club has its obligations in the form of weekly reporting. For some more analysis, see the March 7 post: 3 ways the regulators are making banks suffer for control weaknesses. On top of this, the regulators are being very precise about forcing banks to allocate responsibilities to designated Senior Management Functions (SMFs) so that there is no doubt about who should do what. If you are responsible for RDARR, you will be walking around with a target on your back & front.
Regulatory Inquisition. For fans of Monty Python, remember no one expects the Spanish Inquisition. The regulators are asking some very probing questions, which are tortuously difficult to actually answer. The proverbial $64’000 question is: “Show me where this number came from.” Most big places will struggle with that “lineage’ or traceability challenge. For those not so familiar with the term, think of this like those very useful functions in Excel: Trace Precedents, Trace Dependents. Easy enough in your whizzy Excel spreadsheet, but bloody difficult when dealing with group wide data.
Resource Need. Those two forces and all the technical debt of a legacy system architecture are making reporting very painful. For large organisations pulling together the needed information at Group level from the many left hands of systems, entities and business units, has more in common with doing a 1000-piece puzzle by hand than the instant connectivity and data mining of TV shows like 24.
Data quality is important more often than not. Data Scientists, the very clever tech brethren focussing on “Big Data”, will often not care about the completeness and accuracy of any one data record. If you are trying to show a correlation between mortgage delinquencies and deposits into accounts across a client base of 1 million account holders, then you can easily ignore one incomplete record. If you are helping Credit Suisse with their Digital Banking project to allow account opening in 15 minutes, then data quality really matters; getting the input right, selecting from a drop down list of variables, with the correct metadata and master data behind that. For regulatory reporting, if you have to use defaults where data fields are empty or invalid, then you will default to worst, potentially overstating capital needs and risks.
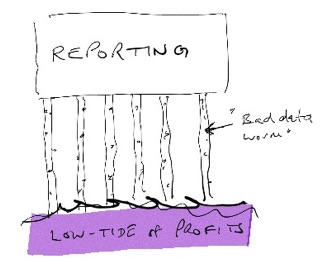
The tide is out
Banks are not making profits as easily as they have in the past. With all the burdens on the reporting processes, the effect of the “bad data worm” are more visible than ever before.
A major cause of the pain which organisations feel is down to the way in which information is collected, prepared and presented. For example, Capital Reporting is a separate application from Regulatory Reporting. Those input files will often be sourced multiple times and almost certainly the same data fields appear in many different input fields. Data handling rules are then written at the field level for each feed. It is easy to see how the rules for any one field will get out of sync across multiple feeds going to any one platform. On the output side, because the data has been sourced from different input feeds across multiple processes, it is a big assumption to think there is data consistency across those outputs.
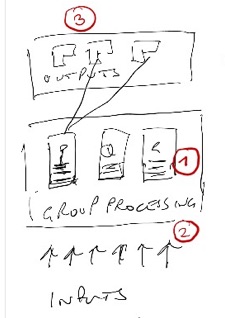
Apart from the huge human effort to write and maintain code to support those many feeds, the tech side is heavy too. The data warehouse solutions which house the applications and data are very expensive to buy and maintain.
“Golden source”
This has been a battle cry in the financial services industry for many a year. Common sense, if one may use that in the same breath as banks, says that if you have only one and only one source of cleansed data and make all systems take data from there, then your problems are solved. Brilliant theory. On top of that “old wisdom” comes the fact that new technology is by degrees cheaper and more powerful. “Moore’s Law” is not new either.
The latest wisdom, which we can call “Big Data”, suggests we all need a data lake as that one single source. Hadoop is one example of this new technology. Our IT brethren will positively salivate as they describe all the analytics they can perform on this giant pool of data.
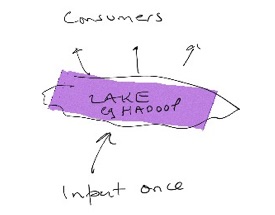
Easier said than done
If the lake is to be that golden source and not a data swamp, then a lot of governance and organisation needs to be added to the mix. If one business division simply wants to dump a copy of their own data to analyse, then yes, the analytics stuff will look very sexy indeed. That is not enough to have a solid golden source of data for the whole organisation.
Controlled Data
The first key ingredient is to realise that a data lake must be a central solution. Federal not federated. Typically, organisations will have been set up along business and entity lines. Those silos come with processes and procedures for IT change & development. Living in Switzerland, I think of this as a state or cantonal organisation. In Switzerland, the cantons, and even below them, the “Gemeinden” or cities, are very independent; think Asterix & Obelix vs. the Romans. Large organisations are much the same. Setting up a big data programme with a data lake and “hoping they will come” is not enough. One person needs to be put in charge and given the remit to force the transformation from the status quo.
Then comes ownership. You need to think about inputs & outputs. Determining a set of owners for the input side is not so hard; you might, for example, divide into domains. Client data might be one, master data another. Then there is a need to appoint a business owner for the new platform; this necessarily must be at a group level.
The business owner then has to set some data information & quality standards. At most, two levels might need to coexist: group common data and other. As soon as information is being used to provide aggregate reporting either externally or internally, there has to be one set of standards, using one set of tools and one methodology. If only one business is going to use the data and only for reporting, then some minimum information will do the job.
Selecting, or rather agreeing on a common toolset is hard. Especially in the initial phases, when no one tool has established itself. For managing data quality, one single tool is essential. The group level business owner has to be able to monitor across all domains and then hold the domain owners accountable to manage quality to an agreed standard.
As you work to impose data quality, spare a thought for central vs. local needs. As the business owner of group data, you might want to monitor 20 fields out of the 100 in a feed. The domain owner might though want to monitor another 15. That wider need must never be an excuse for the domain owner to use different tools. Instead, the central perform owner must ensure that the one set of federal tools is used.
Ensuring data quality needs a very disciplined approach; each field in each feed has to be mapped to a common term. This will be part of the data taxonomy. This will let you discover where different systems name the same thing differently. For each common term, you need some rules. Those rules are the vital step in getting out of the legacy nightmare of individually coding for every field in every feed. This also allows you to say that data corresponding to the term A is sourced from Feed A, field 27, Feed N, field 137 etc.
| Data Controls | Group Common Data | Other |
| Inventory: what data has been loaded to the platform, where is it from and which parties service it? | Y | Y |
| Delivery Quality: did the data delivery arrive, was it complete, was it plausible? | Y | Y |
| Data Quality: are individual fields complete and is the content in line with the rules? | Always | Sometimes |
If you then choose a technology stack, in the first instance, overall costs go up not down; you are paying for new and old. You need a migration plan and a committed budget to get there. There are several ways to skin the cat. From many conversations with experienced tech wizards, I would recommend starting with an inventory of the outputs and working backwards. So, for a group of related outputs work back to the inputs, then source those into the new stack, add the data quality part, then migrate so these reports are coming from the new stack.
Some good news from the offset. If Data Quality issues are fixed at source, then even after this first step, any consumers of the improved data are benefitting.
At this point, the legacy inputs might be going into both old and new. Eventually, you will get to the point where you can turn off the legacy inputs. That is why you need a plan and some very good communications around business costs & benefits. Migration of this kind will never be quick, it is bound to stretch over multiple years. A project in that state is an easy target for the latest cost savings and cutback efforts.
Lessons to be Learned:
Golden source: large organisations need one and only one source of the truth. That implies a Group level data service and a long term jihad to ensure local data capture is eradicated.
The Big Data prize: the latest tech does indeed offer the prospect of substantially lower operational costs, but getting from old to new is hard work down in the trenches.
It’s all about the move; moving house is often really helpful for ridding yourself of old stuff you were never using. Committing your organisation to that journey for data and putting the resources behind that transformation will offer you the chance to take control of your data.
But, and it is a huge one, you have to stick to the plan.
Many thanks to long-time colleague and mentor, Barry Lewis from Elixirr, for his advice & help in shaping this article.
About the Author: I help banks master their post trade processing; optimising, re-engineering, building.
I understand the front-to-back and end-to-end impact of what banks do. That allows me to build the best processes for my clients; ones that deliver on the three key dimensions of Operations: control, capacity and cost.
Previous Posts
Are available on the 3C Advisory website, click here.
Publications
The Bankers’ Plumber’s Handbook
Control in banks. How to do operations properly.
For some in the FS world, it is too late. For most, understanding how to make things work properly is a good investment of their time.
My book tries to make it easy for you and includes a collection of real life, true stories from nearly 30 years of adventures in banking around the world. True tales of Goldman Sachs and collecting money from the mob, losing $2m of the partners’ money and still keeping my job and keeping an eye on traders with evil intentions.
So you might like the tool kit, you might like the stories or you might only like the glossary, which one of my friends kindly said was worth the price of the book on its own. Or, you might like all of it.
Go ahead, get your copy!
Hard Copy via Create Space: Click here
Kindle version and hard copy via Amazon: Click here

Cash & Liquidity Management
An up to date view of the latest issues and how BCBS guidance that came into force from Jan 1 2015 will affect this area of banking. Kindle and hard copy.
Hard Copy via Create Space: Click here
Amazon UK: Click here
Amazon US: Click Here
Share on: